


Avec la Raspberry Pi AI HAT+ 2, Raspberry Pi propose une carte intégrant directement un accélérateur Hailo-10H et 8 Go de mémoire dédiée, conçue pour le Raspberry Pi 5. Cette carte permet d’exécuter localement des modèles d’IA générative, des LLM et des Vision-Language Models, sans recours au cloud. L’AI HAT+ 2 délivre jusqu’à 40 TOPS en INT4, tout en libérant la mémoire du Pi pour le reste de l’application. Connectée via le PCIe Gen 3 et parfaitement intégrée à Raspberry Pi OS, elle vise des usages concrets en vision, vocal, robotique et automatisation embarquée.
Dans cette partie 1, je valide l’installation et le premier modèle LLM en local. La partie 2 couvrira les usages et performances.
Au sommaire :
- 1 Raspberry Pi AI HAT+ 2 : Hailo-10H et 40 TOPS pour l’IA embarquée sur Pi 5 (Partie 1)
- 1.1 Architecture et répartition des rôles Pi 5 / AI HAT+ 2
- 1.2 Matériel de départ : Raspberry Pi 5 (8 Go) + microSD 64 Go
- 1.3 Installation de Raspberry Pi OS (Trixie) avec Raspberry Pi Imager v2
- 1.4 Installer les dépendances de base
- 1.5 Installer HailoRT depuis les sources
- 1.6 Installation de Docker
- 1.6.1 Préparer l’installation de Docker
- 1.6.2 Préparer l’ajout du dépôt Docker
- 1.6.3 Ajouter la clé de signature du dépôt Docker
- 1.6.4 Rendre la clé Docker lisible par APT
- 1.6.5 Déclarer le dépôt Docker dans APT
- 1.6.6 Mettre à jour la liste des paquets APT
- 1.6.7 Installer le moteur Docker
- 1.6.8 Vérifier que Docker fonctionne correctement
- 1.6.9 Démarrer Docker automatiquement au démarrage
- 1.6.10 Autoriser l’utilisateur à utiliser Docker sans sudo
- 1.6.11 Vérifier l’accès à Docker sans privilèges administrateur
- 1.7 Préparer le support noyau (DKMS)
- 1.8 Installer la pile Gen-AI Hailo (model zoo + backend Ollama)
- 1.9 Construire Hailo-Ollama depuis les sources
- 1.10 Premier test d’inférence (API /api/chat)
- 1.11 Conclusion
- 1.12 Sources
Raspberry Pi AI HAT+ 2 : Hailo-10H et 40 TOPS pour l’IA embarquée sur Pi 5 (Partie 1)
Architecture et répartition des rôles Pi 5 / AI HAT+ 2
Sur un Raspberry Pi 5, l’AI HAT+ 2 n’est pas un “coprocesseur magique” qui remplace le CPU : c’est un accélérateur IA (Hailo-10H) relié au Pi via l’interface PCIe Gen 3. Le Pi 5 conserve donc tous les rôles “système” : démarrage, réseau, stockage, gestion des capteurs, orchestration logicielle, et préparation des données (images caméra, audio, texte, etc.). L’AI HAT+ 2, lui, prend en charge la partie la plus coûteuse : l’inférence IA (exécution des modèles), avec une latence plus stable et une consommation contenue. En pratique, ton application tourne sur le Pi 5, et elle “délègue” au HAT les calculs IA compatibles (vision, LLM/VLM quantifiés, post-traitements), pendant que le Pi s’occupe du reste : affichage, API, enregistrement, logique métier et automatisation.
Ces 8 Go de RAM ne sont pas là pour “booster” la RAM du Raspberry Pi 5 : ils servent à héberger et alimenter le Hailo-10H en données de travail (poids de modèles quantifiés, buffers, activations, lots d’images, contextes, etc.). Résultat : les modèles “gourmands” peuvent tourner plus sereinement sans monopoliser la mémoire du Pi, qui reste disponible pour Linux, le cache disque, l’UI, Docker, la capture caméra, les logs, la base de données, etc. Dit autrement : le Pi 5 pilote et assemble le pipeline, et la carte garde une mémoire dédiée pour que l’inférence reste fluide et prévisible, surtout quand on empile caméra + traitement + interface + réseau en même temps.
Matériel de départ : Raspberry Pi 5 (8 Go) + microSD 64 Go
Pour cette installation, je pars sur une base simple et propre : un Raspberry Pi 5 avec 8 Go de RAM, démarré sur une microSD de 64 Go. L’objectif est d’obtenir un système Trixie fraîchement installé, stable, et prêt à recevoir la suite (pilotes, outils, et la carte IA ensuite).
Vérification rapide côté stockage
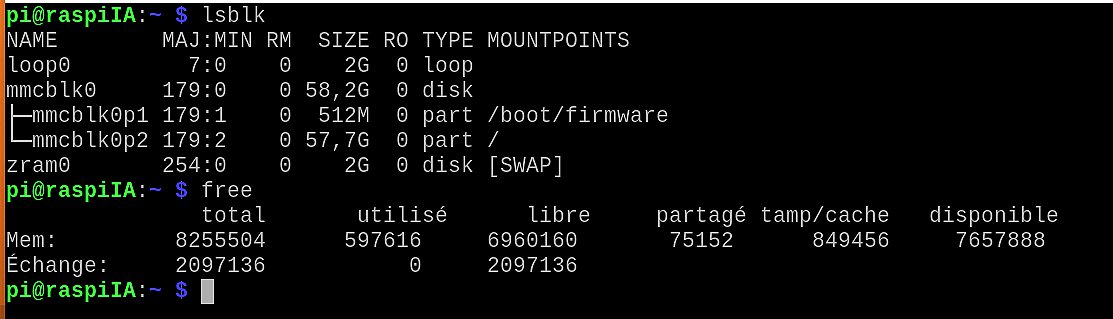
Voici ce que retourne lsblk sur la carte microSD :
- mmcblk0 : la microSD (~58,2 Go utiles)
- mmcblk0p1 : partition /boot/firmware (512 Mo)
- mmcblk0p2 : partition / (le système, ~57,7 Go)
Vérification rapide côté mémoire
Le free confirme bien un Pi 5 8 Go (environ 8,2 Go visibles), avec un swap en zram (2 Go) activé :
- RAM : ~8 Go
- Swap : ~2 Go via zram (compression en RAM)
Installation de Raspberry Pi OS (Trixie) avec Raspberry Pi Imager v2

L’outil le plus simple pour préparer une microSD propre est Raspberry Pi Imager v2. Il s’occupe de tout : téléchargement de l’image, écriture, vérification, et options de pré-configuration.
Étape 1 : Préparer l’écriture
- Insérez la microSD (64 Go) dans le lecteur SD du PC/MAC/Raspberry Pi.
- Lancez Raspberry Pi Imager v2.
- Cliquez sur Device et sélectionnez Raspberry Pi 5.
- Cliquez sur OS et choisissez une image Raspberry Pi OS (Trixie) ici Desktop.
- Cliquez sur Stockage et sélectionnez la microSD
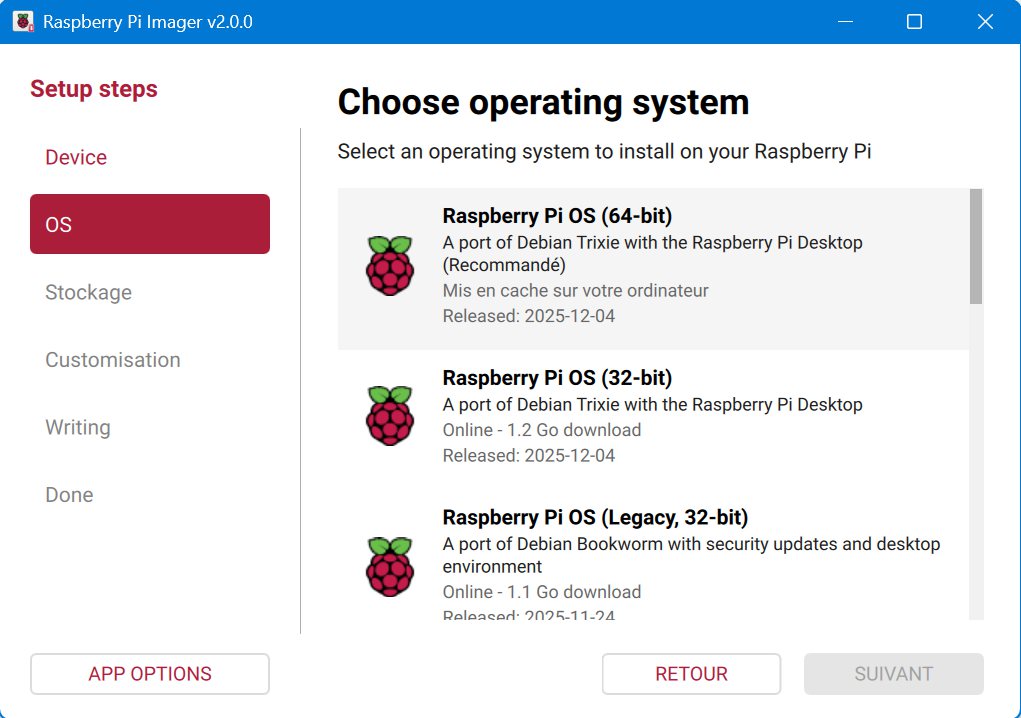
Étape 2 : Options utiles (recommandé)
Avant d’écrire, Imager propose généralement des options (roue dentée / “Edit settings”). Pour éviter les manipulations après coup, il est pratique de régler dès maintenant :
- Nom d’hôte (hostname) : par exemple
raspiIA - Utilisateur : création du compte (ou réglage du mot de passe)
- Wi-Fi : SSID + mot de passe (si démarrage en Wi-Fi)
- SSH : activation (utile si pilotage à distance)
- Locale : langue, clavier, fuseau horaire
Étape 3 : Écriture de la carte
- Cliquez sur Write.
- Laissez Imager terminer l’écriture puis la vérification.
- Éjectez proprement la microSD.
- Insérez la microSD dans le Raspberry Pi 5 et démarrez.
Point important : à ce stade, l’objectif est juste d’avoir un Trixie “propre” qui boote, avec réseau/SSH si souhaité. La partie carte IA (AI HAT+ 2) arrive ensuite, étape par étape. C’est la configuration recommandée par Raspberry Pi pour la mise en route de la carte AI HAT+ 2.
Étape 4 : Mise à jour du système
sudo apt update sudo apt full-upgrade -y sudo reboot
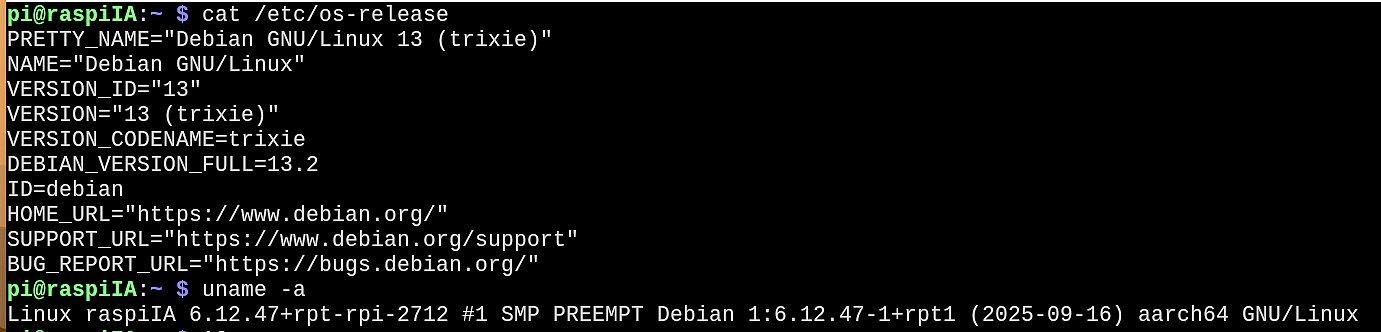
On a une bonne base de départ : Debian 13 trixie, kernel 6.12 rpi, aarch64. On peut continuer…
Installer les dépendances de base
Avant de compiler HailoRT depuis les sources, il est nécessaire d’installer les outils de développement indispensables (compilateur, CMake, bibliothèques système et environnement Python). Ces dépendances permettent de construire correctement les composants natifs et de vérifier que la chaîne de compilation du système est cohérente
sudo apt install -y build-essential cmake pkg-config git python3 python3-venv python3-dev python3-pip libudev-dev libpci-dev libusb-1.0-0-dev
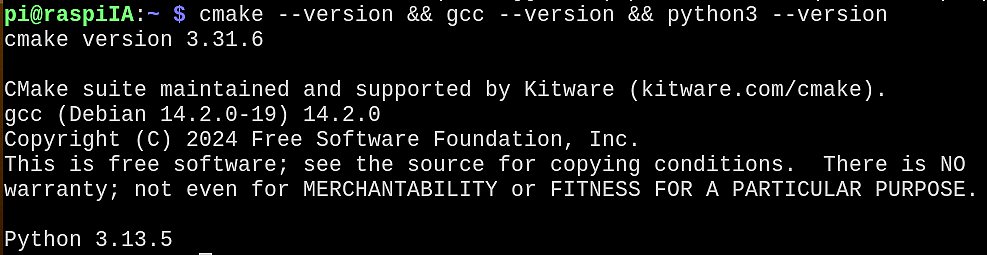
Le test avec cmake, gcc et python3 confirme que l’environnement est prêt pour une compilation sans erreur.
cmake --version && gcc --version && python3 --version
Installer HailoRT depuis les sources
Cloner HailoRT
HailoRT (Hailo Runtime) est la couche logicielle qui permet au système d’exploitation de dialoguer avec l’accélérateur IA Hailo présent sur l’AI HAT+ 2. Elle fournit les bibliothèques, les services et les outils nécessaires pour charger des modèles, gérer les échanges de données et piloter l’exécution des inférences sur le NPU. Sans HailoRT, la carte Hailo n’est pas exploitable par les applications. L’installer et le compiler depuis les sources permet de garantir une compatibilité optimale avec la version du noyau et de Debian utilisée, tout en évitant les problèmes parfois rencontrés avec des paquets précompilés.
mkdir -p ~/hailo/src cd ~/hailo/src && git clone https://github.com/hailo-ai/hailort.git
La commande git status permet de vérifier que le dépôt HailoRT a été correctement cloné, que l’on se trouve bien sur la branche attendue et qu’aucune modification locale n’est présente avant de commencer la compilation.
cd ~/hailo/src/hailort && git status
Le passage sur un tag précis avec git checkout permet de figer le code source de HailoRT sur une version identifiée et stable. Cela garantit que la compilation et les tests seront reproductibles, indépendamment des évolutions ultérieures du dépôt principal.
👉 Pour Debian 13 (Trixie) + Hailo-10H / AI HAT+ 2, on part sur la version stable la plus récente : v5.1.1 (API stabilisée, support GenAI à jour). (tapez git tag pour avoir la liste des versions)
git checkout v5.1.1
On peut créer le répertoire de build
mkdir -p build && cd build
Configuration du build de HailoRT
Puis générer la configuration de build. Lors de cette étape de configuration avec CMake, HailoRT ne se contente pas de générer les fichiers de compilation. Le système peut également récupérer et préparer automatiquement certaines dépendances externes, comme protobuf, nécessaires au fonctionnement du runtime. Cette phase s’effectue en arrière-plan et peut prendre plusieurs minutes, en fonction de la connexion réseau et des performances de la machine. Laissez la commande aller au bout avant de continuer.
cmake ..

Après 7 minutes cmake rend la main.
Compilation de HailoRT
La commande make lance la compilation effective de HailoRT à partir des fichiers générés par CMake. L’option -j$(nproc) indique à l’outil de compilation d’utiliser tous les cœurs processeur disponibles sur la machine. La commande nproc retourne automatiquement le nombre de cœurs du système disponibles, ce qui permet d’accélérer significativement la compilation sans avoir à le renseigner manuellement. Sur un Raspberry Pi 5, cette parallélisation réduit sensiblement le temps de compilation, au prix d’une charge CPU élevée temporaire et d’une élévation de la température CPU, ce qui est un comportement normal.
make -j$(nproc)
Installation de HailoRT sur le système
Cette étape copie les bibliothèques, outils et en-têtes compilés vers les emplacements système.
sudo make install

On vérifie que HailoRT fonctionne bien :
hailortcli --version

Note sur les versions
À la date d’écriture de cet article (décembre 2025), la documentation officielle annonce HailoRT 4.23 comme version de référence pour Raspberry Pi OS Trixie via l’installateur unifié hailo-all. Dans cet article, certaines briques (HailoRT, Hailo-Ollama) ont été compilées depuis les sources GitHub afin de documenter finement la chaîne logicielle et valider le fonctionnement bas niveau de la carte. Les deux approches sont compatibles, la méthode unifiée simplifiant désormais l’installation pour la majorité des utilisateurs.
Installation de Docker
Préparer l’installation de Docker
Pour exécuter les composants LLM et l’interface Web associés à la carte Hailo-10H, la documentation recommande l’utilisation de Docker. Cette approche permet d’isoler les dépendances logicielles (notamment Python) et d’éviter les problèmes de compatibilité avec Debian 13 (Trixie), en particulier avec Python 3.13. Avant d’installer Docker lui-même, il est nécessaire de disposer des outils permettant de gérer les certificats et de télécharger les clés de signature des dépôts officiels.
Avant d’ajouter le dépôt Docker, nous installons deux outils de base : ca-certificates et curl. Les certificats permettent au système de vérifier l’identité des serveurs HTTPS (éviter un dépôt “faux” ou intercepté), et curl sert à récupérer la clé GPG et tester rapidement des URLs. C’est une étape simple, mais indispensable pour réaliser une installation propre et sécurisée.
sudo apt install -y ca-certificates curl

Sur une Trixie « fraîche », les certificats sont souvent déjà présents. Mais on confirme surtout que l’environnement est OK, et ça évite des surprises plus loin.
Préparer l’ajout du dépôt Docker
Avant d’ajouter le dépôt officiel de Docker, il est nécessaire de créer un emplacement dédié pour stocker les clés de signature (GPG) des dépôts APT. Ce mécanisme permet à Debian de vérifier l’authenticité des paquets téléchargés et d’éviter l’installation de logiciels provenant de sources non fiables. Cette étape ne modifie pas encore le système, elle prépare simplement un environnement sécurisé pour la suite de l’installation.
sudo install -m 0755 -d /etc/apt/keyrings
La commande install -m 0755 -d /etc/apt/keyrings crée le répertoire /etc/apt/keyrings s’il n’existe pas déjà, avec des permissions adaptées au système. L’option -d indique qu’il s’agit de créer un dossier, et -m 0755 définit les droits d’accès : lecture et exécution pour tous les utilisateurs, écriture réservée à l’administrateur.
Ajouter la clé de signature du dépôt Docker
Pour que Debian puisse faire confiance au dépôt Docker, il faut d’abord importer sa clé de signature (GPG). Cette clé permet à APT de vérifier que les paquets Docker téléchargés sont bien authentiques et n’ont pas été modifiés. Sans cette étape, le dépôt serait refusé par le système.
sudo curl -fsSL https://download.docker.com/linux/debian/gpg -o /etc/apt/keyrings/docker.asc
Rendre la clé Docker lisible par APT
Après avoir téléchargé la clé GPG du dépôt Docker, il faut s’assurer qu’elle est lisible par le système de gestion des paquets. APT doit pouvoir accéder à cette clé pour vérifier la signature des paquets lors des mises à jour et des installations.
sudo chmod a+r /etc/apt/keyrings/docker.asc
Déclarer le dépôt Docker dans APT
Maintenant que la clé de signature est en place, il faut déclarer officiellement le dépôt Docker auprès du gestionnaire de paquets APT. On écrit le fichier docker.sources avec un echo … | tee. Cette étape sert à dire à APT où trouver Docker (le dépôt officiel) et avec quelle clé il doit vérifier les paquets. Sans ça, apt install docker… ne trouvera rien (ou pire : pas la bonne source).
echo "Types: deb URIs: https://download.docker.com/linux/debian Suites: trixie Components: stable Signed-By: /etc/apt/keyrings/docker.asc" | sudo tee /etc/apt/sources.list.d/docker.sources
La suite trixie est indiquée explicitement afin d’éviter les problèmes d’affichage ou de copie liés aux substitutions de variables dans certains éditeurs.
Mettre à jour la liste des paquets APT
Après avoir ajouté un nouveau dépôt, le gestionnaire de paquets APT doit recharger la liste des logiciels disponibles. Cette mise à jour permet au système de prendre en compte le dépôt Docker que nous venons de déclarer et de vérifier que les paquets associés sont bien accessibles et correctement signés.
sudo apt update
Ici on voit que le dépôt Docker a bien été pris en compte. On peut continuer avec l’installation de Docker.
Installer le moteur Docker

Docker est surtout utile pour lancer une interface type WebUI sans se battre avec les dépendances Python.
sudo apt install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
Docker est une plateforme de conteneurisation : elle vous permet d’exécuter une application dans un conteneur, c’est-à-dire un environnement d’exécution isolé et léger.
L’idée clé : vos applications peuvent cohabiter sur la même machine sans “se marcher dessus”.
Un conteneur embarque tout ce dont l’application a besoin (dépendances, bibliothèques, config…), mais sans embarquer un système d’exploitation complet comme une machine virtuelle. Il partage le noyau (kernel) du système hôte, ce qui le rend généralement plus léger et plus rapide à démarrer/arrêter qu’une VM.
Pensez “boîte hermétique” : l’application vit dans sa boîte avec ses outils, et votre machine peut héberger plusieurs boîtes sans conflits.
En pratique, Docker s’appuie notamment sur des images (modèles en lecture seule) pour créer des conteneurs (instances en cours d’exécution), et vous manipulez tout ça via le Docker Engine (le “moteur”).
Vérifier que Docker fonctionne correctement
Après l’installation, il est important de vérifier que le moteur Docker est opérationnel et que le service démarre correctement. Cette vérification permet de s’assurer que Docker peut lancer des conteneurs avant d’aller plus loin avec les services Hailo et les LLM.
sudo docker run hello-world
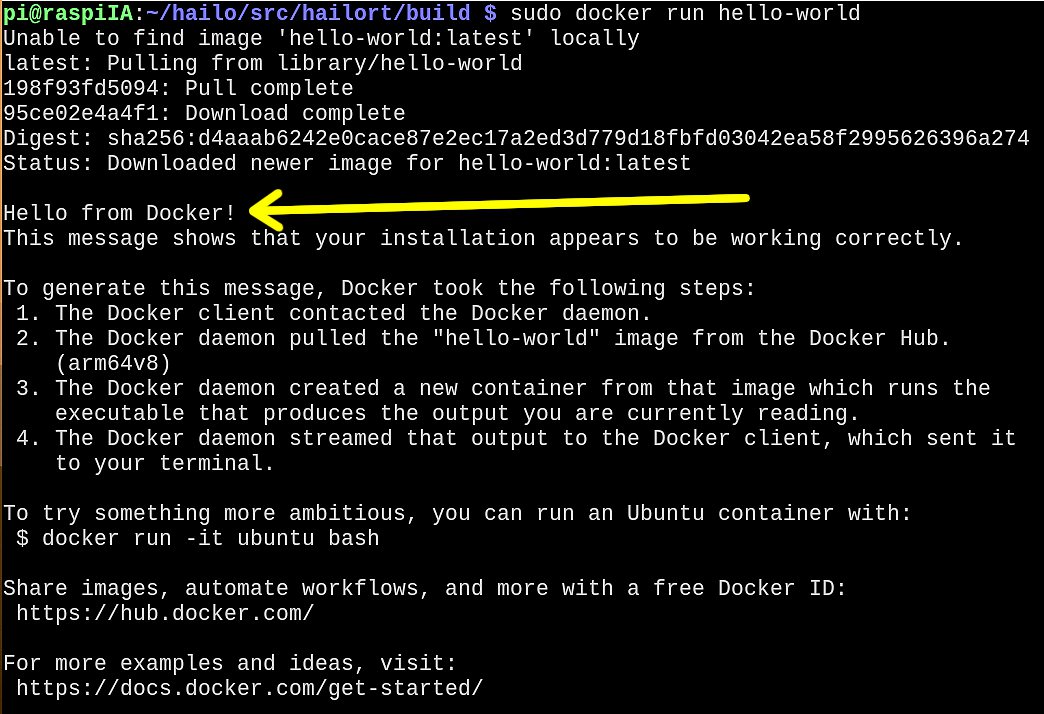
Et voilà : Docker fonctionne correctement.
Démarrer Docker automatiquement au démarrage
Maintenant que Docker est installé et fonctionnel, il est préférable de l’activer au démarrage du système. Cela évite d’avoir à lancer le service manuellement après chaque reboot et garantit que les conteneurs nécessaires (LLM, WebUI) pourront démarrer automatiquement.
sudo systemctl enable docker

C’est bon, Docker est maintenant activé automatiquement au démarrage.
Autoriser l’utilisateur à utiliser Docker sans sudo
Par défaut, Docker nécessite les privilèges administrateur. Pour un usage courant (tests, scripts, services LLM), il est plus pratique d’autoriser l’utilisateur courant à exécuter les commandes Docker sans préfixer systématiquement par sudo. Cette étape ajoute simplement l’utilisateur au groupe système docker.
Note : le groupe docker équivaut quasiment à des droits root sur la machine.
sudo usermod -aG docker $USER sudo reboot
⚠️ Important : ce changement prend effet après la prochaine déconnexion / reconnexion (ou reboot). D’où la seconde ligne qui redémarre l’OS.
Vérifier l’accès à Docker sans privilèges administrateur
Après le redémarrage, il est important de vérifier que l’utilisateur courant peut désormais utiliser Docker sans sudo. Cette vérification confirme que l’appartenance au groupe docker est bien prise en compte et que l’environnement est prêt pour lancer les services LLM.
docker run hello-world
et vous devez obtenir le message Hello from Docker ! comme précédemment.
Préparer le support noyau (DKMS)
Pour que les composants Hailo puissent s’intégrer correctement au noyau Linux (gestion du matériel, mises à jour du kernel), la documentation prévoit l’utilisation de DKMS (Dynamic Kernel Module Support). DKMS permet de reconstruire automatiquement les modules nécessaires lorsqu’un noyau est mis à jour.
👉 Même si nous avons compilé HailoRT depuis les sources, DKMS reste un prérequis propre et standard pour la suite de la pile Hailo.
sudo apt install -y dkms
Installer la pile Gen-AI Hailo (model zoo + backend Ollama)
Le binaire hailo-ollama n’est pas fourni par HailoRT. Il fait partie de la pile Gen-AI Hailo, souvent appelée Gen-AI Model Zoo, qui fournit :
- le backend compatible Ollama,
- les scripts et services nécessaires pour charger et exécuter des LLM optimisés Hailo-10H.
Avant de pouvoir lancer hailo-ollama, cette couche logicielle doit donc être installée explicitement.
Cloner le dépôt Gen-AI Hailo
cd ~ && git clone https://github.com/hailo-ai/hailo_model_zoo_genai.git
Le dépôt GenAI Hailo que nous venons de cloner correspond à la couche applicative de la pile logicielle Hailo : il contient les modèles, le backend compatible Ollama et les éléments nécessaires à l’interface Web.
Cependant, cette couche ne peut fonctionner que si le système d’exploitation dispose déjà d’un accès opérationnel à l’accélérateur Hailo-10H. Autrement dit, avant de lancer un serveur LLM ou une interface utilisateur, il est indispensable que le noyau Linux sache dialoguer avec le matériel.
Vérifier l’accès au matériel Hailo
Avant d’activer la pile GenAI, il est nécessaire de vérifier que le système d’exploitation reconnaît bien l’accélérateur Hailo-10H. Cette vérification permet de confirmer que le matériel est présent et accessible au niveau du bus PCIe, avant d’installer les composants logiciels qui s’appuient dessus.
lspci | grep -i hailo

Une ligne mentionnant Hailo apparaît, cela confirme que la carte est bien détectée par le système. Cette commande ne dépend d’aucun driver spécifique, c est une commande standard Linux.

Si rien ne s’affiche, le problème est matériel (carte, alimentation, montage). Dans ce cas il faut résoudre le problème avant de continuer.
Ajouter le dépôt APT Hailo (repo de test)
Avant de pouvoir installer le driver noyau Hailo-10H (hailo-h10-all), il est nécessaire d’ajouter le dépôt APT de test Hailo fourni par Raspberry Pi. Ce dépôt contient les paquets spécifiques au Hailo-10H et n’est pas inclus dans les dépôts Debian standards.
À la date d’écriture de cet article (décembre 2025), cette procédure est indispensable pour accéder aux composants Hailo, mais il est probable que ce dépôt soit intégré automatiquement à Raspberry Pi OS lors de la sortie officielle de la carte, rendant cette étape inutile à terme. Dans un terminal, saisissez :
printf '%s\n' \ 'Types: deb' \ 'URIs: https://hailo:chahy5Zo@extranet.raspberrypi.org/hailo' \ 'Suites: trixie' \ 'Components: main' \ 'Signed-By: /usr/share/keyrings/raspberrypi-archive-keyring.pgp' \ | sudo tee /etc/apt/sources.list.d/hailo.sources
Actualiser la liste des paquets
Après l’ajout du dépôt Hailo, le gestionnaire de paquets doit recharger la liste des paquets disponibles afin de rendre accessibles les composants spécifiques au Hailo-10H.
sudo apt update

À propos de l’avertissement APT affiché : Lors de la mise à jour des paquets, APT peut afficher un avertissement indiquant que les informations d’identification sont intégrées directement dans le fichier de dépôt (sources.list.d/hailo.sources). Ce message recommande l’utilisation de apt_auth.conf, un mécanisme plus récent permettant de stocker séparément les identifiants.
À la date d’écriture de cet article, cette configuration est celle recommandée par la documentation officielle. Il est probable que cette étape évolue ou disparaisse lors de l’intégration définitive du dépôt Hailo dans Raspberry Pi OS, auquel cas cet avertissement ne sera plus affiché.
On voit ici qu’il y a des fichiers à mettre à jour et apt list –upgradable montre que les noyaux et les headers en font partie ! Avant d’installer le driver noyau Hailo-10H via DKMS, il est recommandé de mettre à jour le système, en particulier le noyau Linux et ses en-têtes. Cela permet à DKMS de compiler le module directement pour la version finale du noyau, évitant ainsi une recompilation inutile ou des incohérences après mise à jour.
sudo apt upgrade sudo reboot

Installer le driver noyau Hailo-10H (via DKMS)
DKMS (Dynamic Kernel Module Support) est un système qui permet d’installer des modules noyau (drivers bas niveau) de façon “propre” sur Linux.
Le point important : quand le noyau Linux est mis à jour (nouvelle version de linux-image), certains drivers doivent être recompilés pour rester compatibles. Sans DKMS, on se retrouve parfois avec un driver qui “casse” après une mise à jour… et un matériel qui n’est plus reconnu.
Dans notre cas, le Hailo-10H a besoin d’un driver noyau. En passant par DKMS, ce driver est reconstruit automatiquement lors des mises à jour du noyau du Raspberry Pi 5, ce qui évite les mauvaises surprises et garantit que l’accélérateur reste utilisable dans la durée.
Maintenant que le système est à jour, en particulier le noyau Linux et ses en-têtes, nous pouvons installer le driver noyau Hailo-10H. Celui-ci est fourni sous forme de paquet s’appuyant sur DKMS, ce qui garantit que le module sera automatiquement recompilé en cas de future mise à jour du noyau. Cette étape est indispensable pour rendre l’accélérateur Hailo accessible au système et aux couches logicielles supérieures.
sudo apt install hailo-h10-all
Il y a plus de 450 Mo à télécharger et à installer… Soyez patient(e). Après l’installation du driver noyau Hailo-10H, un redémarrage est nécessaire afin de charger le module kernel et de rendre l’accélérateur accessible au système. Sans ce redémarrage, le périphérique Hailo n’est pas encore utilisable par le runtime.
sudo reboot
Valider l’accès matériel avant d’installer la pile GenAI
Après le redémarrage, il est nécessaire de vérifier que le driver noyau Hailo-10H est correctement chargé et que l’accélérateur est bien accessible depuis le système. La commande suivante permet de confirmer que le runtime Hailo détecte le matériel avant de poursuivre avec les couches logicielles supérieures.
hailortcli scan

La détection du périphérique par hailortcli confirme que le driver noyau Hailo-10H est opérationnel et que le runtime peut dialoguer avec l’accélérateur. Cette validation est indispensable avant d’installer et de lancer la pile GenAI (serveur LLM et interface Web), qui s’appuie sur cet accès matériel.
Construire Hailo-Ollama depuis les sources
.deb ?Installer un paquet .deb est souvent la solution la plus simple, mais dans le cas du Hailo Model Zoo GenAI, compiler depuis les sources présente plusieurs avantages, en particulier sur une plateforme récente comme le Raspberry Pi 5.
En compilant soi-même, on s’assure que le serveur hailo-ollama est construit exactement pour la version du système, du noyau et des bibliothèques présentes (OpenSSL, C++ runtime, etc.). Cela évite les incompatibilités parfois rencontrées avec des paquets pré- compilés.
Cette approche permet aussi de voir clairement quelles dépendances sont utilisées et de mieux comprendre l’architecture logicielle (HailoRT, serveur d’inférence, API Ollama). C’est particulièrement utile dans un contexte d’expérimentation ou de rédaction d’un article technique.
Enfin, compiler depuis les sources offre plus de souplesse : on peut appliquer des correctifs, suivre l’évolution du dépôt officiel, ou adapter facilement la procédure à de futures mises à jour.
Bref, c’est un peu plus long… mais clairement plus mieux pour comprendre ce que l’on fait.
Compiler Hailo-Ollama
À ce stade, HailoRT est installé et la carte est visible via hailortcli scan. On va maintenant compiler le serveur hailo-ollama (API compatible Ollama) directement depuis le dépôt hailo_model_zoo_genai, afin d’éviter tout souci Python sur Debian 13/Trixie.
sudo apt install -y libssl-dev
On commence par installer la dépendance libssl-dev
cd ~/hailo_model_zoo_genai mkdir -p build && cd build cmake -DCMAKE_BUILD_TYPE=Release .. cmake --build .

Installer le serveur hailo-ollama (binaire + config)
La compilation ayant abouti, le serveur hailo-ollama est maintenant disponible dans l’arborescence de build. Il faut à présent l’installer dans le répertoire utilisateur afin de pouvoir le lancer facilement depuis un terminal, sans modifier le système.
mkdir -p ~/.local/bin cp ./src/apps/server/hailo-ollama ~/.local/bin/ mkdir -p ~/.config/hailo-ollama/ cp ../config/hailo-ollama.json ~/.config/hailo-ollama/ mkdir -p ~/.local/share/hailo-ollama cp -r ../models/ ~/.local/share/hailo-ollama

Ajouter ~/.local/bin au PATH
Le binaire hailo-ollama a été installé dans le répertoire utilisateur ~/.local/bin. Pour pouvoir l’exécuter directement depuis un terminal, ce chemin doit être présent dans la variable d’environnement PATH. Si la commande hailo-ollama du paragraphe suivant ne répond pas, c’est généralement que ~/.local/bin n’est pas encore dans le PATH.
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc source ~/.bashrc
~/.local/bin ?Sur un système Linux, il existe deux grandes façons d’installer un programme :
Installation système (/usr/bin, /usr/local/bin)
- nécessite les droits administrateur
- impacte tous les utilisateurs
- engage la responsabilité du gestionnaire de paquets
Installation utilisateur (~/.local/bin)
- ne nécessite pas de privilèges root
- n’impacte que l’utilisateur courant
- facile à modifier ou supprimer
Dans le cas de Hailo-Ollama, l’installation est faite volontairement dans le répertoire utilisateur pour plusieurs raisons :
- Le logiciel est encore en phase active d’évolution
Compiler depuis les sources implique des ajustements fréquents. Installer dans/usrfigerait davantage l’environnement. - Aucun paquet Debian officiel n’est utilisé ici
Le binaire est compilé manuellement : l’installer dans/usrsans gestionnaire de paquets irait à l’encontre des bonnes pratiques Debian. - Sécurité et réversibilité
Supprimer~/.local/bin/hailo-ollamasuffit à désinstaller le serveur, sans laisser de trace système. - Cohérence avec la documentation officielle
La méthode Build from source fournie par Hailo recommande explicitement une installation côté utilisateur.
Démarrer le serveur Hailo-Ollama
La pile LLM fournie par Hailo s’appuie sur un service appelé hailo-ollama. Ce service joue le rôle de serveur d’inférence local : il expose une API compatible Ollama, capable de charger des modèles LLM optimisés pour le Hailo-10H et de traiter les requêtes entièrement en local, sans passer par le cloud.
Le lancer à ce stade permet de vérifier que le driver noyau, HailoRT et le serveur d’inférence fonctionnent correctement ensemble, avant toute intégration avec une interface web ou des outils externes.
hailo-ollama

Le serveur hailo-ollama est désormais opérationnel et écoute sur le port 8000. Cela confirme que l’ensemble de la chaîne (driver noyau Hailo-10H, HailoRT et serveur d’inférence) fonctionne correctement. L’environnement est prêt pour interroger l’API locale et charger des modèles GenAI optimisés pour le Hailo-10H.
Vérifier l’API Hailo-Ollama
Objectif : s’assurer que le serveur répond bien aux requêtes HTTP. Ouvrez un second terminal, exécutez :
curl --silent http://localhost:8000/hailo/v1/list

Résultat : le serveur répond dans le terminal en bas de l’image et il voit les modèles disponibles.
Tester le chargement d’un modèle
Avant de lancer une première requête de discussion, on vérifie que le serveur peut charger réellement un modèle en mémoire. Cette étape valide le chemin complet : serveur → runtime → Hailo-10H → modèle. On choisit volontairement un petit modèle pour un premier test.
curl --silent http://localhost:8000/api/pull -H 'Content-Type: application/json' -d '{ "model": "qwen2:1.5b", "stream": true }'

Ce qu’on obtient ({« status »: »pulling », …}) est normal : le serveur télécharge le modèle en morceaux et renvoie une progression. Ici j’ai interrompu le chargement par CTRL + C ! Laissez le chargement se poursuivre jusqu’à la fin. On voit que le modèle pèse 1,68 Go environ ! Le serveur est en train de télécharger le modèle sur Internet depuis le dépôt Hailo. Il sera stocké localement. L’empreinte cryptographique (hash) du modèle sert à vérifier l’intégrité des données (vérifier que le modèle n’est pas corrompu) … Patientez jusqu’à …

À ce stade : le serveur fonctionne, le modèle est présent localement, tout est prêt pour une première requête d’inférence
Premier test d’inférence (API /api/chat)
Avant toute intégration plus avancée, on valide le fonctionnement complet de la chaîne en envoyant une requête simple au modèle fraîchement chargé. On va lui faire traduire une phrase : The cat is on the table
curl --silent http://localhost:8000/api/chat -H 'Content-Type: application/json' -d '{"model":"qwen2:1.5b","messages":[{"role":"user","content":"Translate to French: The cat is on the table."}]}'

Ce que confirment ces lignes c est que la chaine fonctionne : API → serveur → runtime → accélérateur → modèle → réponse
- le serveur hailo-ollama est actif
- le modèle est bien chargé en local
- l’inférence s’exécute sur le Hailo-10H
- l’API /api/chat répond correctement
- le streaming de tokens fonctionne
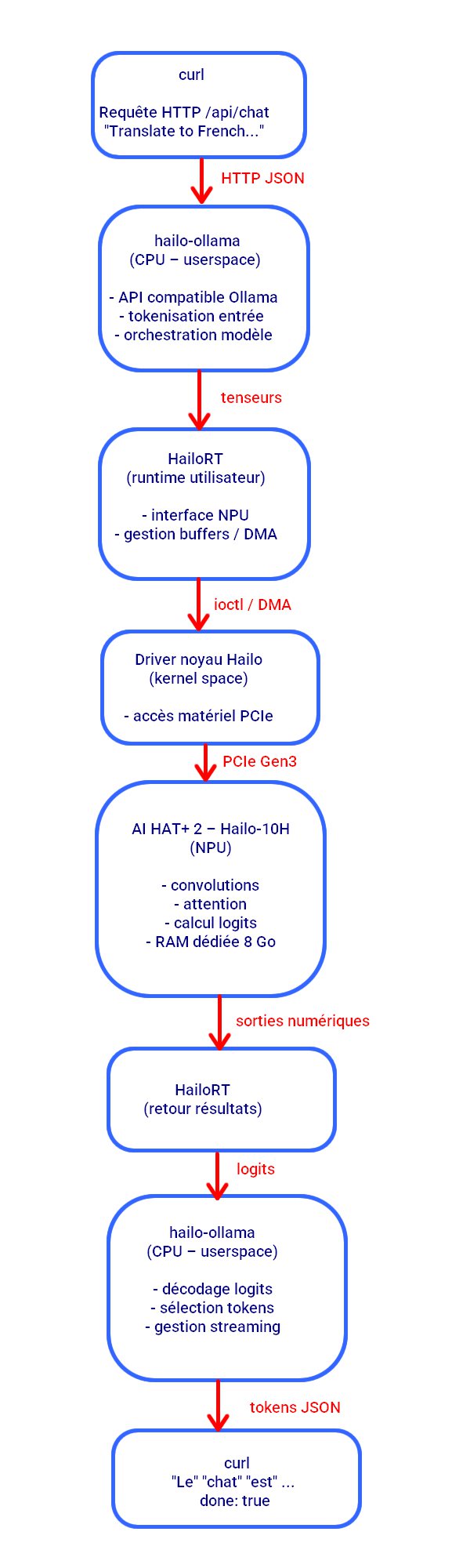
Déroulement du test
Conclusion
La première étape est validée : la réponse progressive confirme que l’inférence s’exécute bien en local via le Hailo-10H. Le serveur hailo-ollama fonctionne conformément à l’API compatible Ollama, en streaming, sans recours au cloud.
La suite (mesures de performances, essais de modèles plus gros, cas d’usage concrets, et ajout d’une interface type WebUI) fera l’objet d’un deuxième article dédié.
Dans la partie 2, on mesurera latence, débit de tokens, et on testera des modèles plus gros + une WebUI.
La pile logicielle Hailo (driver noyau, runtime, outils et applications) évolue rapidement, en particulier autour du support du Raspberry Pi 5 et de Debian 13 (Trixie).
La procédure décrite dans cet article est documentée et validée à la date d’écriture (décembre 2025). Elle a été suivie pas à pas afin de comprendre finement les différentes couches de la pile (noyau, runtime, serveur d’inférence) et de valider le bon fonctionnement de la carte AI HAT+ 2 / Hailo-10H.
Depuis, Hailo propose une installation unifiée via le paquet hailo-all, qui simplifie considérablement la mise en place pour la majorité des utilisateurs. Cette méthode regroupe driver, runtime et outils dans un flux d’installation plus direct. L’approche détaillée ici reste néanmoins pertinente pour la compréhension, le diagnostic et les usages avancés, notamment dans un contexte d’expérimentation ou d’analyse technique.
Sources
https://www.raspberrypi.com/products/ai-hat-plus-2/https://pip-assets.raspberrypi.com/categories/1319-raspberry-pi-ai-hat-2/documents/RP-009655-MM-3-raspberry-pi-ai-hat-plus-2-product-brief.pdfhttps://www.raspberrypi.com/documentation/accessories/ai-hat-plus.htmlhttps://hailo.ai/products/hailo-software/model-explorer/generative-ai/devices/hailo-10h/https://hailo.ai/products/ai-accelerators/hailo-10h-m-2-ai-acceleration-module
https://datascientest.com/docker-guide-complet
Les articles sur Framboise314 :
Raspberry Pi AI HAT+ 2 : présentation matérielle et installation sur Raspberry Pi 5
Raspberry Pi AI HAT+ 2 : installer Hailo-10H et lancer un LLM local (Partie 1)
https://www.framboise314.fr/raspberry-pi-ai-hat-2-hailo-10h-video-partie-2/
Ping : Raspberry Pi AI HAT+ 2 : test matériel et installation sur Raspberry Pi 5 (Hailo-10H)